Contents
- Overview
- Data model
- Terminology
- Assigning validation tier to a rule
- Utility stored procedures
- Summary
- Related topics
1. Overview
The purpose of this third part of the three-part series on the SQL data validation framework is to provide more detailed information on some features of the framework, which you may want to know about especially if you are considering building your own data validation process using this framework.
2. Data model
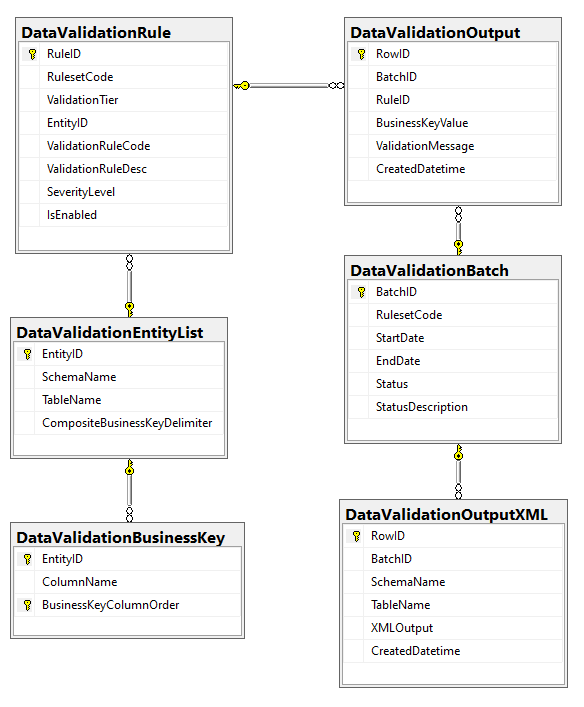
A validation rule definition is stored collectively by three tables as below:
- DataValidationEntityList
- DataValidationBusinessKey
- DataValidationRule
The validation rules itself are implemented in stored procedures.
The validation output is written to DataValidationOutput table.
These four tables are described in detail as below:
2.1 DataValidationEntityList table
DataValidationEntityList table stores names of tables to validate. For example: Customer.
2.2 DataValidationBusinessKey table
It is a requirement of the data validation framework that a table that’s being validated must have a business key or a surrogate key, to identify individual records in a table.
A business key can be a single column or a multi-column composite key. It can be a surrogate key or a natural key.
If the business key of an entity is a composite key, then we’ll also need to specify a delimiter. Additionally, the order of those multiple columns that make up a composite key is to be specified as well. It is made use of in validation output to generate business key values by concatenating column values in the same column order as specified in DataValidationBusinessKey table. For example, a composite business key value using ‘~’ as separator in the output table could look: C008~1 (which was a combination of customer ID and addressSequenceNo).
It is preferable to have unique or near-unique business key values in the table being validated. Near-uniqueness is acceptable, if not perfectly unique, accommodating the possibility that the data to be validated might contain duplicates on the business key. Saying that, if there was hardly any uniqueness in the business key, then the validation output could be of limited use as we cannot identify offending rows as precisely as possible. In other words, more unique a business key is, better it is to uniquely identify the offending records in the output.
2.3 DataValidationRule table
The DataValidationRule table contains definitions of validation rules while the rules itself are implemented in stored procedures.
The columns of the DataValidationRule table are briefly described as below, while some of those columns will be described further in the next section:
| Column name | Description |
| ValidationRuleCode | An identifier / label for a rule. |
| ValidationRuleDesc | A brief business description of the rule |
| EntityID | Represents an entity/table the rule is associated with |
| SeverityLevel | The severity of the rule – Error / Warning More details available in the next section. |
| IsEnabled | Tells the validation process if the rule was to be executed or not. More details available in the next section. |
| ValidationTier | A validation tier is a sub-set of validation rules, whose grouping is determined taking dependency requirements among the rules into consideration. More details available in the next section. |
| RulesetCode | A name given to a collection of rules that are executed as a single validation processing batch. More details available in the next section. |
Note: For additional information including example data in these rule definition tables, refer to 2. Example article
2.4 DataValidationOutput table
As and when a validation rule is executed, if there were any rows of data that broke a given rule, the record identifiers of such rows are written to DataValidationOutput table.
While doing so, it captures the below information:
| Column name | Description |
| RuleID | The validation rule that the row brok |
| BusinessKeyValue | Value of the businessKey of the row |
| ValidationMessage | This column is intended to capture any additional information that might help with resolving data issues. |
| BatchID | Tells us the BatchID that the output is part of. Each time a validation process is started after a previously successful run, it would be assigned a new BatchID. On the other hand, if the previous run of the process failed for whatever reason, then the last BatchID would be reused. In such a case, the previously logged output of the failed BatchID is removed while re-starting from the beginning or resuming from where it failed |
3. Terminology
3.1 RulesetCode
A RulesetCode can be seen as a label to a collection of validation rules. It is specified in DataValidationRule table.
Why do we need a RulesetCode?
It gives us the ability to set up multiple collections of validation rules in the framework, in the event we need to set them up for whatsoever reason.
Some example scenarios where you might need to have different collections of rules are:
- Scenario 1: You are extracting data from your data warehouse for two different regulatory authorities. Each of them has their own set of validation rules to apply while uploading our data into their system.
- Scenario 2: You are receiving data from two different source systems. Each source system’s data requires to be subjected to a different set of validation rules.
If you just have a single collection of validation rules, you may just give it a default name to it and refer to that name wherever it is required.
3.2 Severity Level of Validation Rule
There are two severity levels supported by the framework.
- Severity level E (Error)
- Severity level W (Warning)
Severity level E (Error): Say, we have set up a validation rule with a severity level of E (ERROR). When the validation process was run, let us say some records in a staging table broke that rule. In such a case, those records in staging table get marked as IsValid = false. Additionally, the business keys of such records are written to the validation output table. Optionally, such invalid records could be excluded from loading to destination.
Severity level W (Warning): Unlike severity level E (Error), when records in staging table broke a severity level W (Warning), the staging records’ IsValid flag isn’t affected. Because the rule broken was just a warning and not a business-critical rule. However, the fact this rule was broken is still logged to the validation output table along with the business keys of the affected rows.
Tip: If a row had broken multiple business rules and if any of the broken business rules was of severity level E, then such row gets marked as invalid in staging table.
Note: A row marked as invalid in a staging table by the validation process wouldn’t get automatically excluded from loading to destination. If you choose to exclude such records from loading to destination, then explicit coding changes in ETL will need to be made.
3.3 IsEnabled column in DataValidationRule table
Firstly, every staging table that’s going to be validated by this framework requires a IsValid column in it.
The IsValid column serves two purposes:
- Whenever records in a staging table broke a validation rule of severity E (ERROR), the validation process will mark the corresponding rows in the staging table as invalid by setting those records’ IsValid = false.
- It helps in implementing multi-tier validation rules.
Saying that, you may still be able to get away by not having ‘IsValid’ column in the staging tables, especially if NONE of the validation rules for that table were of severity level E. However, you might be limited in your ability to perform multi-tier level validations. Consider testing thoroughly before finalising your decision to not have IsValid column in a staging table.
3.4 Validation Tiers
A validation tier implies two things:
- all the rules that belong to a validation tier can be executed without any dependency on other rules within the same tier
- the rules in a higher validation tier (say, tier 1) should be executed only after the rules in its lower tier (say, tier 0 in this example) are executed.
Every validation rule is to be assigned to a validation tier. A validation tier may contain one or many rules assigned to it.
How to determine as to which validation rule goes in which validation tier? The next section has information on it.
Note: Validation tiers are just logical tiers and intended as a guide while implementing them in stored procedures. But, the framework itself wouldn’t stop you from executing any rule at any stage regardless of what validation tier it belongs to.
4. Assigning validation tier to a rule
4.1 Assigning validation tier to a rule
As indicated earlier, a validation tier assigned to a rule denotes a sequential order that a rule is intended to be executed. There can be multiple rules within the same tier, as long as there was no dependency among the rules executed in the same validation tier.
But, how do I determine as to which validation tier a given rule goes into?
It depends on the validation rules that you want to implement. The value assigned should take into consideration the dependency between the rules.
It will likely to be an iterative process to get the sequential order of execution of validation rules correct, depending upon how complicated the dependencies between your rules are.
4.2 Validation tier identification – starting point
As a good starting point for identifying validation tier for a rule, you may want to get an answer to the “rule dependency basic question” as below:
Has the validation rule in question depends on any other validation rules to be executed first?
4.3 Assigning rules to tier 0:
If NO is the answer to the “rule dependency basic question”, then that rule can be assigned to tier 0. In theory, such independent rule could be assigned to any tier and not just to tier 0. However, it is recommended to assign it to tier 0 so that there would be a smaller number of rules to handle in tier 1 and higher. The rules in tier 1 and higher are likely to have inter-dependency issues to handle. So, smaller the number of rules in higher tiers, better it is.
A classic example of rule that can go in tier 0 is – say we want to implement a rule to check for duplicate business keys (say Customer ID) in customer table. Checking for duplicate business keys doesn’t have dependency on other rules. So, this is a tier 0 rule.
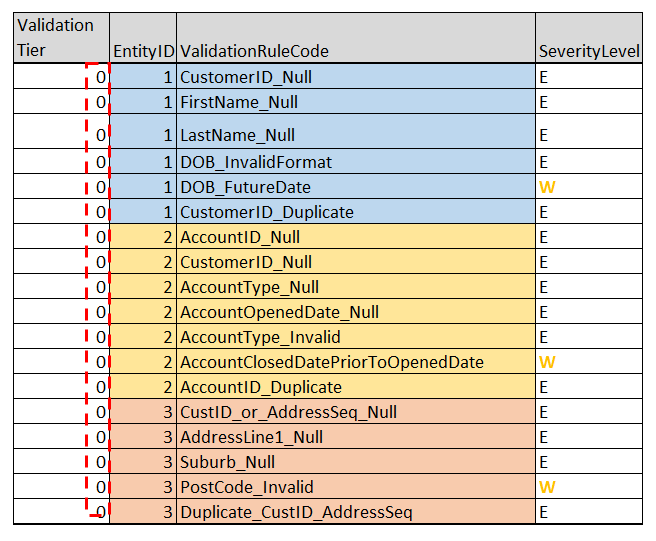
Similarly, the rules from the example data validation process that fall into tier 0 are as below:
The other common examples of tier 0 rules include checking for NOT NULL values, data types, check constraints, date format etc.
Can a cross-entity validation rule be placed in tier 0?
It depends. For example, say your SQL query was joining the base table (staging table) to another reference data / look up table. Assuming your lookup data table isn’t one of those tables that is going to be validated by the current validation process, it’s OK to join to the other table. However, if you want to join to another table that is also going to be validated in the remainder of the validation process, then it is safer to place such rule into tier 1 or higher taking the rule dependency needs into consideration.
4.4 Assigning rules to tier 1 or higher:
If YES was the answer to the “rule dependency basic question”, then that rule must go into tier 1 or higher.
While it is straight forward to assign a rule to tier 0, there’s no magic formula to assign it to one of the higher tiers.
It all depends on the dependencies between the rules. I want to reiterate here that it is the dependency between the rules rather than between the entities, that drives the validation tier assignment. The parent-child relationships would play a supporting role but not necessarily a primary role in this regard.
Continuing with the example validation rules, the following rules were assigned tier 2 and tier 3, for the reasons explained below:

In the figure 3.3, the two rules at tier 2 belong to customer table (Entity ID: 1) and have a dependency on the rules of account/address table. Because, before executing these two rules of customer, we’ll need to validate account and address to determine if there are valid or not.
In this particular example validation rules, account and address were already validated in tier 0 and tier 1.
So, these two rules of customer were assigned tier 2.
Now, the remaining two rules in the figure 3.3 are at tier 3. They were assigned tier 3 because they depend on the validation of its parent (customer). The parent itself was being validated in tier 2.
Note: In hindsight, the example validation rules as in figure 3.4 which were placed in tier 1 in the example validation process could very well have been assigned to tier 0 itself. However, it doesn’t have any side-effects of assigning to tier 1. So, the tier assignment for these example rules was left unaltered.

5. Utility stored procedures
There are about a dozen utility stored procedures as below that you can find in the source code. They are required for the data validation framework. They are generic, reusable and independent of entities being validated.
- usp_DataValidation_CheckNecessityOfIsValidColumn
- usp_DataValidation_Cleanup_BeforeRerun
- usp_DataValidation_CreateOrGetBatchID
- usp_DataValidation_Generate_JOIN_clause_On_BusinessKeys
- usp_DataValidation_Generate_ORDER_BY_clause_on_BusinessKeyCols
- usp_DataValidation_Generate_WHERE_clause_BusinessKey_NULL
- usp_DataValidation_GetEntityID
- usp_DataValidation_Generate_XML_Output
- usp_DataValidation_GetValidationRule
- usp_DataValidation_Mark_Invalid_Rows
- usp_DataValidation_UpdateBatchStatus
- usp_DataValidation_ValidateEntityAndRulesSetup
6. Summary
All the three parts of the article on data validation framework have now been covered.
The part 1 introduced the framework at a high level along with discussing the salient features, benefits, pre-requisites and limitations of the framework.
The part 2 demonstrated an example data validation process that was built based on this data validation framework. At the same time, it contained lot of useful information that can be useful in understanding the framework.
The part 3 contained additional and more detailed information about some of the features of the framework that may not have been described in detail in part 1 and 2.
7. Related topics
This article was the 3rd of the three-part series on SQL data validation framework. For other parts of this article including video presentations of the same, refer to the below links:
